In this post, we are going to learn about the operating system kernel parameters, shared memory, and semaphores.
But why?
As we all know, PostgreSQL highly interacts with the operating system parameters for the operations that it does on the database.
Understanding the operating system resource limits is one of the important things for a PostgreSQL DBA.
Before we deep dive into the PostgreSQL usage of kernel parameters, we first understand the basics of inter-process communication.
This tutorial is divided into two sections.
1. Operating system basics.
2. PostgreSQL usage and Case study.
Table of Contents
Operating system basics
What is a process and what is Inter-process communication?
A process is a series of actions or steps to achieve something.
A process within a system may be independent or cooperative. If the process is independent it is not affected by the execution of other processes on the other side if it is cooperative, it can be affected by other processes.
Interprocess communication is a mechanism which allows processes to communicate with each other and synchronize their actions.
Linux Kernel provides different types of IPC mechanisms of which PostgreSQL uses System V and POSIX IPC mechanisms.
System V or POSIX IPC refers to a set of mechanisms that allow a User Mode process to do the following:
1. Shared memory allows processes to share parts of their virtual address space.
2. Semaphores allow processes to synchronize execution.
3. Messages allow processes to send formatted data streams to arbitrary processes.
PostgreSQL requires the operating system to provide inter-process communication (IPC) features, specifically shared memory and semaphores.
So, we limit our discussion to shared memory and semaphores.
Shared memory:
Shared memory is one of the three interprocess communication (IPC) mechanisms available under Linux and other Unix-like systems.
Upon a new process request, a shared memory segment is created by the kernel and mapped to the data segment of the address space of a requesting process.
How shared memory works?
When data from one process needs to be shared with another process, The first process simply writes data into the shared memory segment.
As soon as it is written, the data becomes available to the second process.
POSIX shared memory files are provided from a tmpfs filesystem mounted at /dev/shm.
Semaphores
semaphore acts as a synchronization tool in IPC systems with the help of which we can ensure that a critical section can be accessed by the processes in a mutually exclusive way.
It is simply a variable or abstract data type used to control access to a common resource by multiple processes in interprocess communication.
PostgreSQL usage and Case study:
PostgreSQL Shared Memory:
When a new client connection request comes to the postmaster process, the postmaster process calls fork() to create a child one for handling the incoming request.
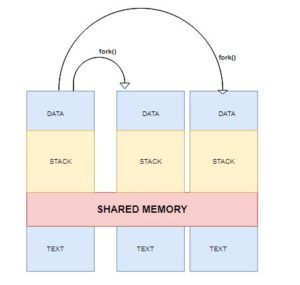
PostgreSQL saves the cache blocks in the memory area called “shared buffer”, and they are shared among multiple back-end processes.
The shared buffer that PostgreSQL instance uses is configured by System V Shared Memory or POSIX.
System V Shared Memory in Linux environment is created using the shmget system call.
For the creation of the System V Shared Memory, a unique key number and size on the host must be specified.
The key number is generated using the following formula.
Shared Memory Key = parameter “port” * 1000 + 1
Since the standard port number waiting for a connection (parameter port) is 5,432, key of the shared memory is 5,432,001 (= 0x52e2c1)
Inadequate settings may lead to the following error.
|
1 2 3 4 5 6 7 8 9 10 11 |
FATAL: could not create shared memory segment: Invalid argument DETAIL: Failed system call was shmget(key=5432001, size=37879808, 03600). HINT: This error usually means that PostgreSQL's request for a shared memory segment exceeded your kernel's SHMMAX parameter. You can either reduce the request size or reconfigure the kernel with larger SHMMAX. To reduce the request size (currently 37879808 bytes), reduce PostgreSQL's shared_buffers parameter (currently 4096) and/or its max_connections parameter (currently 103). If the request size is already small, it's possible that it is less than your kernel's SHMMIN parameter, in which case raising the request size or reconfiguring SHMMIN is called for. |
PostgreSQL Semaphores:
For the locking between each process, Semaphores are utilized. The number of the semaphore set is not changed even if the number of the connecting client increases.
When using System V semaphores, PostgreSQL uses one semaphore per allowed connection (max_connections), allowed autovacuum worker process (autovacuum_max_workers) and allowed background process (max_worker_processes), in sets of 16.
Each such set will also contain a 17th semaphore which contains a “magic number”, to detect collision with semaphore sets used by other applications.
The maximum number of semaphores in the system is set by SEMMNS, which consequently must be at least as high as max_connections plus autovacuum_max_workers plus max_worker_processes, plus one extra for each 16 allowed connections plus workers.
Inadequate settings may lead to the following error.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 |
[postgres@postgreshelp data]$ <2019-01-01 00:51:13.266 IST>FATAL: could not create semaphores: No space left on device DETAIL: Failed system call was semget(5432019, 17, 03600). HINT: This error does *not* mean that you have run out of disk space. It occurs when either the system limit for the maximum number of semaphore sets (SEMMNI), or the system wide maximum number of semaphores (SEMMNS), would be exceeded. You need to raise the respective kernel parameter. Alternatively, reduce PostgreSQL's consumption of semaphores by reducing its max_connections parameter. The PostgreSQL documentation contains more information about configuring your system for PostgreSQL. <2019-01-01 00:51:13.273 IST>LOG: database system is shut down |
We can check the shared memory and semaphore usage with the following command.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 |
[postgres@postgreshelp data]$ [postgres@postgreshelp data]$ ipcs -a ------ Shared Memory Segments -------- key shmid owner perms bytes nattch status 0x00000000 196609 postgres 600 393216 2 dest 0x00000000 229378 postgres 600 393216 2 dest 0x00000000 262147 postgres 600 393216 2 dest 0x00000000 294916 postgres 600 393216 2 dest 0x0052e2c1 1277957 postgres 600 56 5 0x00000000 327686 postgres 600 393216 2 dest 0x00000000 360455 postgres 600 393216 2 dest 0x00000000 393224 postgres 600 393216 2 dest 0x00000000 425993 postgres 600 393216 2 dest 0x00000000 458762 postgres 600 393216 2 dest 0x00000000 491531 postgres 600 393216 2 dest 0x00000000 557068 postgres 600 393216 2 dest 0x00000000 589837 postgres 600 393216 2 dest 0x00000000 622606 postgres 600 393216 2 dest 0x00000000 655375 postgres 600 393216 2 dest 0x00000000 688144 postgres 600 393216 2 dest 0x00000000 720913 postgres 600 393216 2 dest ------ Semaphore Arrays -------- key semid owner perms nsems 0x0052e2c1 9240578 postgres 600 17 0x0052e2c2 9273347 postgres 600 17 ------ Message Queues -------- key msqid owner perms used-bytes messages [postgres@postgreshelp data]$ ipcs -l ------ Shared Memory Limits -------- max number of segments = 1024 max seg size (kbytes) = 4294967296 max total shared memory (kbytes) = 17179869184 min seg size (bytes) = 1 ------ Semaphore Limits -------- max number of arrays = 128 max semaphores per array = 250 max semaphores system wide = 32000 max ops per semop call = 100 semaphore max value = 32767 ------ Messages: Limits -------- max queues system wide = 7895 max size of message (bytes) = 65536 default max size of queue (bytes) = 65536 |
Conclusion:
It is highly recommended to set the kernel parameters adequately enough in the PostgreSQL environment.
The table here shows about the settings of kernel parameters we need to set on a typical PostgreSQL environment.
Words from postgreshelp
Thank you for giving your valuable time to read the above information. I hope the content served your purpose in reaching out the blog.
Suggestions for improvement of the blog are highly appreciable. Please contact us for any information/suggestion/feedback.
If you want to be updated with all our articles
please follow us on Facebook | Twitter
Please subscribe to our newsletter.


