Table of Contents
Short description of the components used
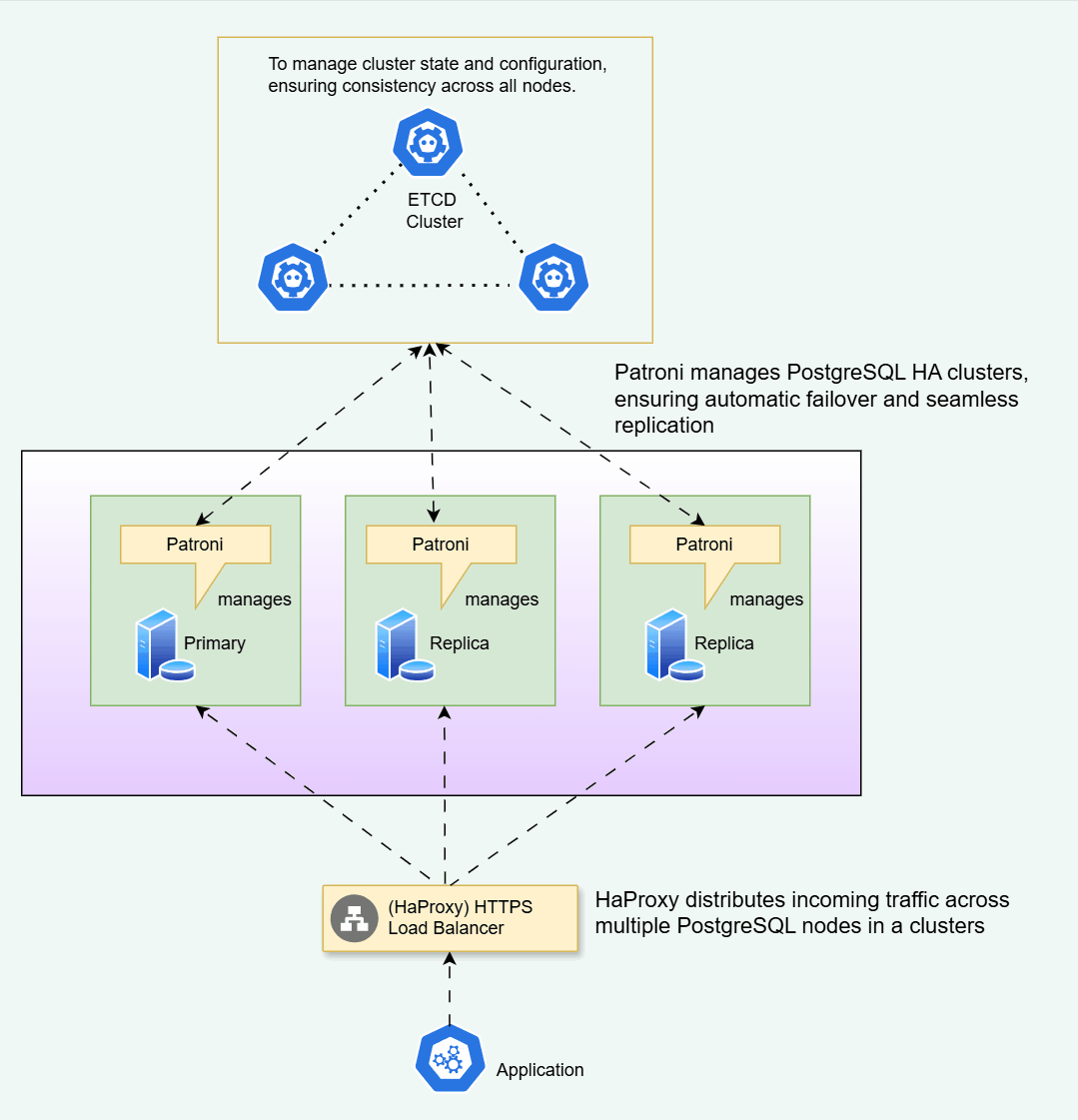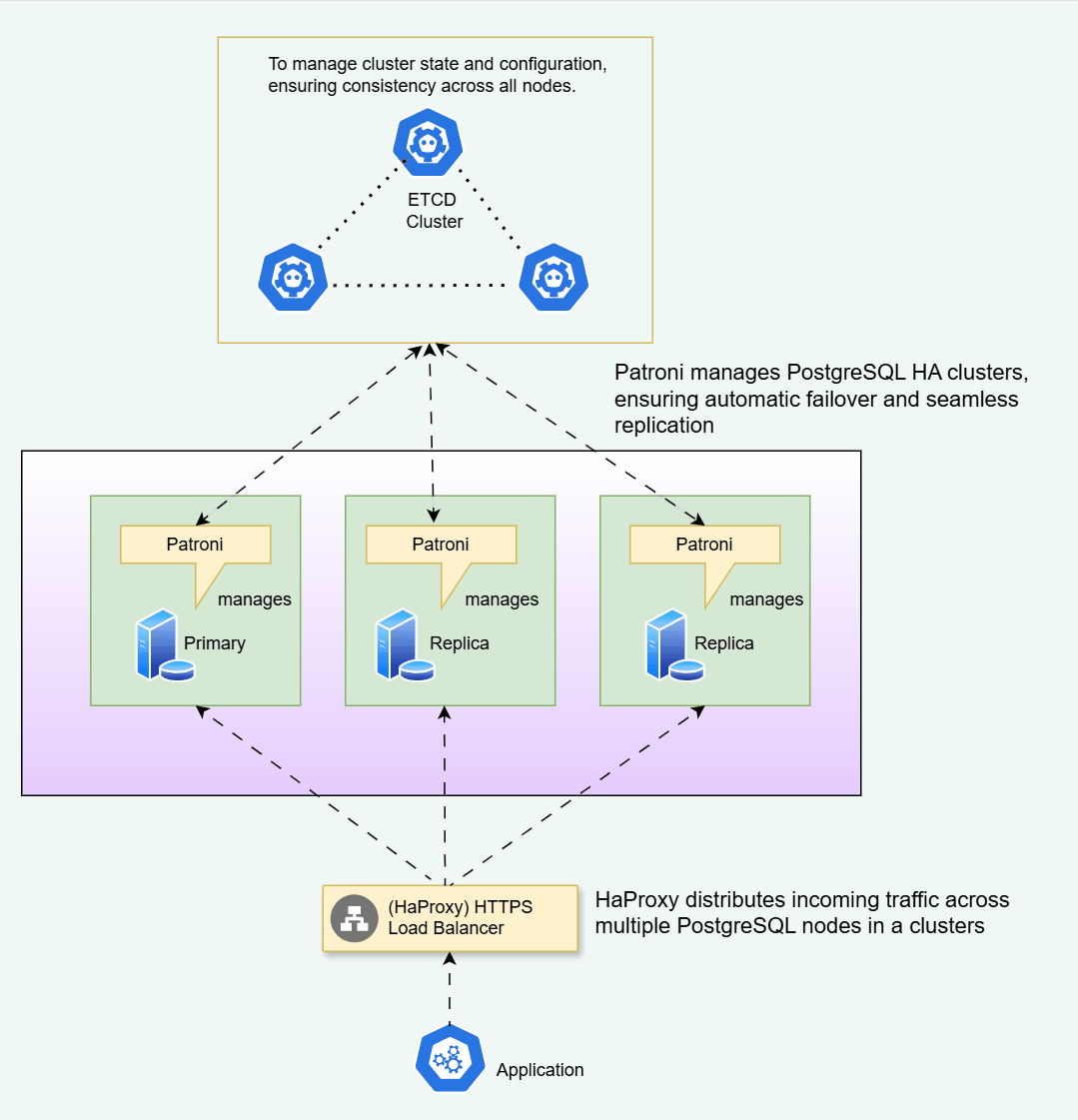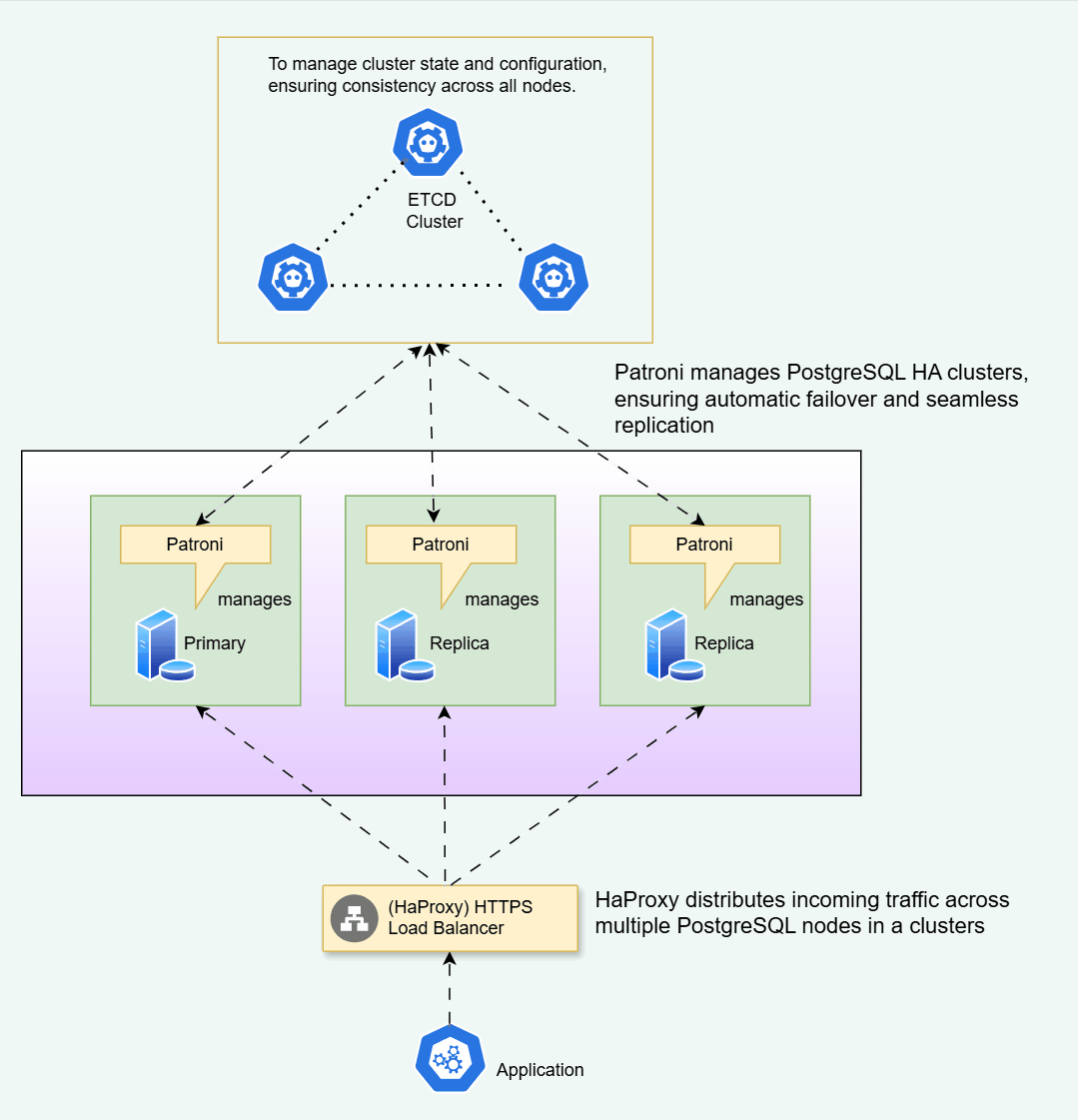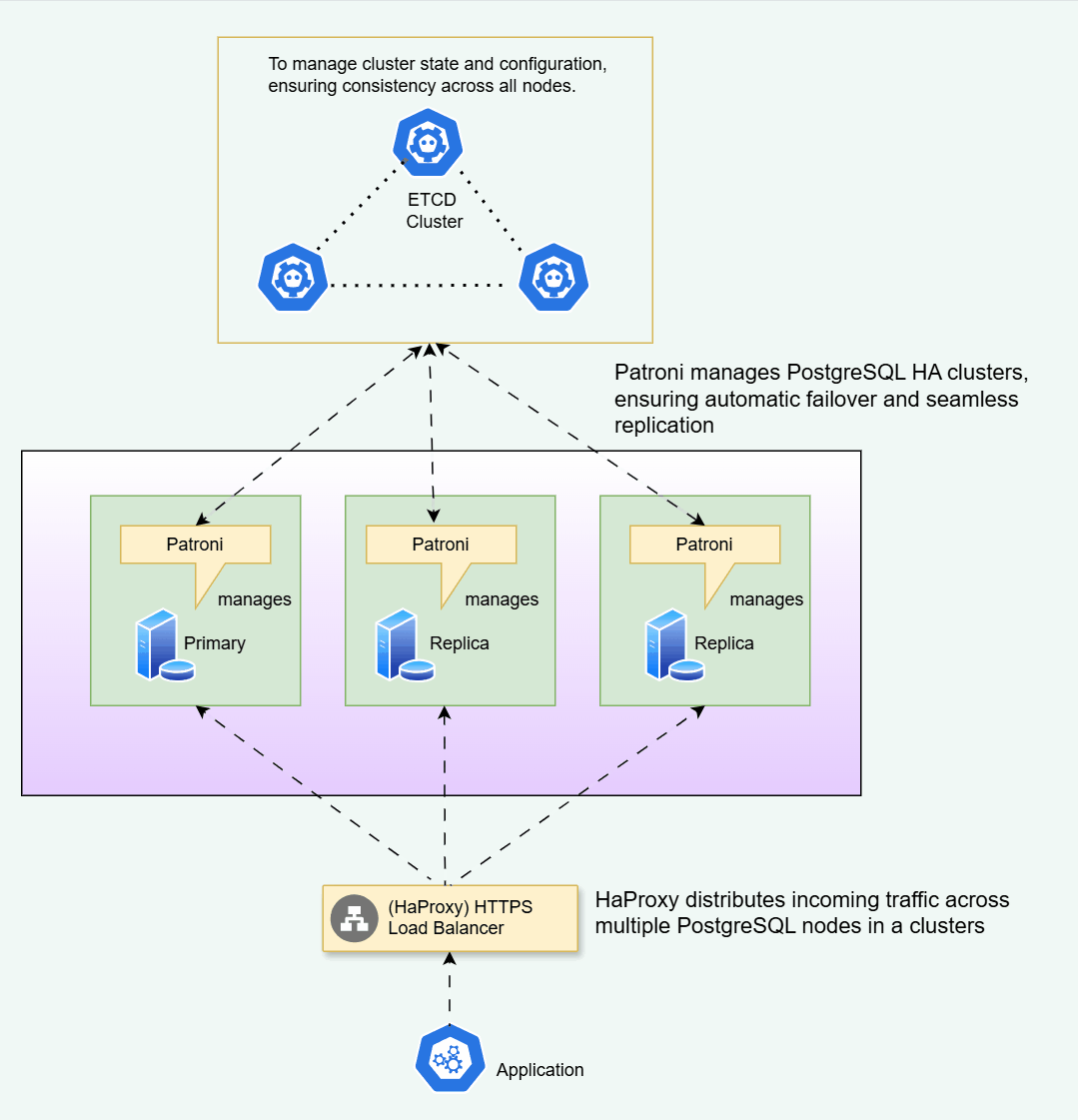
Patroni:
Patroni is an open-source tool used to manage PostgreSQL HA clusters. It’s a lightweight solution that uses the PostgreSQL replication mechanism to ensure that all nodes in the cluster have an up-to-date copy of the database. Patroni provides automatic failover and ensures that only one node is active at any given time.
HAProxy:
HAProxy is a load balancer that can be used to distribute incoming traffic across multiple PostgreSQL nodes in a cluster. It acts as a proxy between clients and the active node in the cluster and ensures that requests are routed to the appropriate node. HAProxy can also detect when a node becomes unavailable and automatically switch to a different node in the cluster.
Keepalived:
Keepalived is a Linux-based software that provides high availability for Linux systems. It can be used to monitor the health of the PostgreSQL nodes and automatically switch the virtual IP address to a healthy node in case of a failure. This ensures that client connections are redirected to the active node in the cluster.
etcd:
etcd is a distributed key-value store used to store configuration data for the PostgreSQL HA cluster. It’s used by Patroni to manage the state of the cluster, and by HAProxy and Keepalived to determine which node is currently active. etcd ensures that the configuration data is consistent across all nodes in the cluster.
Watchdog:
The watchdog process is responsible for monitoring the health of the PostgreSQL node and its associated processes. The watchdog process ensures that the PostgreSQL node is running correctly and that it’s able to serve client requests. If the watchdog detects an issue with the node or its processes, it can take action to recover the node or initiate failover to a standby node.
System Requirements
To follow this tutorial along, you will need a minimum of 3 virtual machines installed with CentOS 9. The purpose is defined is below
| Hostname | IPAddress | Purpose |
| pghelp01 | 192.168.231.128 | etcd, HAProxy, keepalived, Patroni and PostgreSQL, pgBouncer |
| pghelp02 | 192.168.231.129 | etcd, HAProxy, keepalived, Patroni and PostgreSQL, pgBouncer |
| pghelp03 | 192.168.231.130 | etcd, HAProxy, keepalived, Patroni and PostgreSQL, pgBouncer |
| ha-vip | 192.168.231.140 | HA-VIP |
In this lab setup,
- I will use the words pghelp01, pghelp02, etc., to refer to machines 1, 2, and so on. For example., executing “the command in pghelp01″ means executing the command in “192.168.231.128” as mentioned in the table above.
- If I mention [all machines] indicate that commands have to be executed in all machines.
- If I mention [… accordingly] it means you need to make necessary changes as mentioned in the color red in each of the machines.
Pre-requisites
Create postgres user [all machines]
useradd postgres
passwd postgresAdd the user to the /etc/sudoers file
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
postgres ALL=(ALL) NOPASSWD:ALLSet the hostname [all machines accordingly]
sudo hostnamectl set-hostname pghelp01
rebootYou should see something like this
[root@pghelp01 ~]#For Machine 2, it should be
sudo hostnamectl set-hostname pghelp02 reboot
and repeat for pghelp03
Get IP Addresses of all machines and edit /etc/hosts file: [all machines]
vi /etc/hostsadd the below lines
192.168.231.128 pghelp01
192.168.231.129 pghelp02
192.168.231.130 pghelp03
192.168.231.140 ha-vip
Here 192.168.231.140 can be any IP that is not being used and is in the network, I choose 192.168.231.140 randomly. we use this IP address in keepalived configuration below.
Disable Selinux [all machines]
Log in to pghelp01 and edit /etc/selinux/config file with any of your favorite text editor:
vi /etc/selinux/configChange SELINUX=enforcing to SELINUX=disabled
SELINUX=disabledReboot to make the selinux changes effect:
rebootConfigure Firewalld
To set up Patroni for PostgreSQL with additional components like HAProxy, etcd, Keepalived, Pgbouncer, and web servers the following ports need to be opened:
- Patroni:
- 8008: This port is used for the HTTP API of Patroni.
- HAProxy:
- 5000: This port is used for HTTP connections to the backend (PostgreSQL service).
- 5001: This port is used for HTTPS connections to the backend (PostgreSQL service).
- etcd:
- 2379: This port is used for etcd client communication.
- 2380: This port is used for etcd server-to-server communication.
- Keepalived:
- 112: This port is used for the Virtual Router Redundancy Protocol (VRRP) communication between Keepalived instances.
- 5405: This port is used for the multicast traffic between Keepalived instances.
- Pgbouncer:
- 6432: This port is used for Pgbouncer client connections.
- PostgreSQL:
- 5432: This port is used for PostgreSQL client connections.
- Web server:
- 5000: This port is used for HTTP connections to the web server.
- 5001: This port is used for HTTPS connections to the web server.
- 7000: This port is used for the reverse proxy connection from the web server to HAProxy.
These ports are required to allow communication between the different components of the setup. However, the specific port configuration can vary depending on your specific setup and requirements. It’s important to adjust firewall rules and network configurations accordingly to ensure the proper functioning and security of the setup.
//End-to-End PostgreSQL Administration Training: Click here
Run the below commands to open above ports [all machines]
firewall-cmd --zone=public --add-port=5432/tcp --permanent
firewall-cmd --zone=public --add-port=6432/tcp --permanent
firewall-cmd --zone=public --add-port=8008/tcp --permanent
firewall-cmd --zone=public --add-port=2379/tcp --permanent
firewall-cmd --zone=public --add-port=2380/tcp --permanent
firewall-cmd --permanent --zone=public --add-service=http
firewall-cmd --zone=public --add-port=5000/tcp --permanent
firewall-cmd --zone=public --add-port=5001/tcp --permanent
firewall-cmd --zone=public --add-port=7000/tcp --permanent
firewall-cmd --zone=public --add-port=112/tcp --permanent
firewall-cmd --zone=public --add-port=5405/tcp --permanent
firewall-cmd --add-rich-rule='rule protocol value="vrrp" accept' --permanent
firewall-cmd --reloadInstall PostgreSQL 17 [all machines]
Since I am going to have PostgreSQL client in p1 to test the configuration, I will install PostgreSQL in all the machines.
dnf install epel-release dnf config-manager --set-enabled crb sudo dnf install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-9-x86_64/pgdg-redhat-repo-latest.noarch.rpm sudo dnf -qy module disable postgresql sudo dnf install -y postgresql17-server postgresql17-contrib postgresql17-devel
Set up etcd for PostgreSQL 17 HA with Patroni
Install etcd [all machines]
dnf install 'dnf-command(config-manager)'
dnf config-manager --enable pgdg-rhel9-extras
dnf install etcdType the following command to install etcd:
dnf -y install etcdConfigure etcd [accordingly]
Edit the configuration file in pghelp01
mv /etc/etcd/etcd.conf /etc/etcd/etcd.conf.orig
vi /etc/etcd/etcd.confAdd following configuration(Give IP address of current machine in all places, ETCD_INITIAL_CLUSTER should get IP addresses of pghelp01, pghelp02,pghelp03):
Add the following configuration and save.
# This is an example configuration file for an etcd cluster with 3 nodes#specify the name of an etcd member
ETCD_NAME=pghelp01
# Configure the data directory
ETCD_DATA_DIR=”/var/lib/etcd/pghelp01“
# Configure the listen URLs
ETCD_LISTEN_PEER_URLS=”http://192.168.231.128:2380,http://127.0.0.1:2380″
ETCD_LISTEN_CLIENT_URLS=”http://192.168.231.128:2379,http://127.0.0.1:2379″
# Configure the advertise URLs
ETCD_INITIAL_ADVERTISE_PEER_URLS=”http://192.168.231.128:2380″
ETCD_ADVERTISE_CLIENT_URLS=”http://192.168.231.128:2379″
# Configure the initial cluster
ETCD_INITIAL_CLUSTER=”pghelp01=http://192.168.231.128:2380,pghelp02=http://192.168.231.129:2380,pghelp03=http://192.168.231.130:2380″
# Configure the initial cluster state
ETCD_INITIAL_CLUSTER_STATE=”new”
# Configure the initial cluster token
ETCD_INITIAL_CLUSTER_TOKEN=”etcd-cluster”
# Configure v2 API
ETCD_ENABLE_V2=”true”
Edit the configuration file in pghelp02
mv /etc/etcd/etcd.conf /etc/etcd/etcd.conf.orig vi /etc/etcd/etcd.conf
Add the following configuration and save.
# This is an example configuration file for an etcd cluster with 3 nodes#specify the name of an etcd member
ETCD_NAME=pghelp02
# Configure the data directory
ETCD_DATA_DIR=”/var/lib/etcd/pghelp02″
# Configure the listen URLs
ETCD_LISTEN_PEER_URLS=”http://192.168.231.129:2380,http://127.0.0.1:2380″
ETCD_LISTEN_CLIENT_URLS=”http://192.168.231.129:2379,http://127.0.0.1:2379″
# Configure the advertise URLs
ETCD_INITIAL_ADVERTISE_PEER_URLS=”http://192.168.231.129:2380″
ETCD_ADVERTISE_CLIENT_URLS=”http://192.168.231.129:2379″
# Configure the initial cluster
ETCD_INITIAL_CLUSTER=”pghelp01=http://192.168.231.128:2380,pghelp02=http://192.168.231.129:2380,pghelp03=http://192.168.231.130:2380″
# Configure the initial cluster state
ETCD_INITIAL_CLUSTER_STATE=”new”
# Configure the initial cluster token
ETCD_INITIAL_CLUSTER_TOKEN=”etcd-cluster”
# Configure v2 API
ETCD_ENABLE_V2=”true”
Edit the configuration file in pghelp03
mv /etc/etcd/etcd.conf /etc/etcd/etcd.conf.orig vi /etc/etcd/etcd.conf
Add the following configuration and save.
# This is an example configuration file for an etcd cluster with 3 nodes#specify the name of an etcd member
ETCD_NAME=pghelp03
# Configure the data directory
ETCD_DATA_DIR=”/var/lib/etcd/pghelp03″
# Configure the listen URLs
ETCD_LISTEN_PEER_URLS=”http://192.168.231.130:2380,http://127.0.0.1:2380″
ETCD_LISTEN_CLIENT_URLS=”http://192.168.231.130:2379,http://127.0.0.1:2379″
# Configure the advertise URLs
ETCD_INITIAL_ADVERTISE_PEER_URLS=”http://192.168.231.130:2380″
ETCD_ADVERTISE_CLIENT_URLS=”http://192.168.231.130:2379″
# Configure the initial cluster
ETCD_INITIAL_CLUSTER=”pghelp01=http://192.168.231.128:2380,pghelp02=http://192.168.231.129:2380,pghelp03=http://192.168.231.130:2380″
# Configure the initial cluster state
ETCD_INITIAL_CLUSTER_STATE=”new”
# Configure the initial cluster token
ETCD_INITIAL_CLUSTER_TOKEN=”etcd-cluster”
# Configure v2 API
ETCD_ENABLE_V2=”true”
Now start the etcd on all the three machines [all machines]
systemctl start etcd
systemctl enable etcd
systemctl status etcdadd below lines in the bash profile [all machines]
pghelp01=192.168.231.128
pghelp02=192.168.231.129
pghelp03=192.168.231.130
ENDPOINTS=$pghelp01:2379,$pghelp02:2379,$pghelp03:2379
Check if etcd has been successfully working with
. .bash_profile
etcdctl endpoint status --write-out=table --endpoints=$ENDPOINTSThe sample output should look like this
[root@pghelp01 ~]# etcdctl endpoint status --write-out=table --endpoints=$ENDPOINTS +----------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | ENDPOINT | ID | VERSION | DB SIZE | IS LEADER | IS LEARNER | RAFT TERM | RAFT INDEX | RAFT APPLIED INDEX | ERRORS | +----------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ | 192.168.231.128:2379 | c7a4178a55519300 | 3.5.12 | 20 kB | false | false | 3 | 10 | 10 | | | 192.168.231.129:2379 | 64970639687069c9 | 3.5.12 | 20 kB | false | false | 3 | 10 | 10 | | | 192.168.231.130:2379 | b9fd2017d1a72703 | 3.5.12 | 20 kB | true | false | 3 | 10 | 10 | | +----------------------+------------------+---------+---------+-----------+------------+-----------+------------+--------------------+--------+ [root@pghelp01 ~]#
Set up keepalived for PostgreSQL 17 HA with Patroni
Install Keepalived [all machines]
dnf -y install keepalivedConfigure Keepalived [all machines]
Edit the /etc/sysctl.conf file to allow the server to bind to the virtual IP address.
vi /etc/sysctl.confAdd the net.ipv4_ip_nonlocal_bind=1 directive, which allows the server to accept connections for IP addresses that are not bound to any of its interfaces, enabling the use of a floating, virtual IP:
net.ipv4.ip_nonlocal_bind = 1
net.ipv4.ip_forward = 1Save and close the editor when you are finished.
Type the following command to reload settings from config file without rebooting:
sudo sysctl --system
sudo sysctl -pCreate /etc/keepalived/keepalived.conf and make necessary changes [all machines accordingly]
Get the interface name of your network with ifconfig
[root@pghelp01 ~]# ifconfig
ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 192.168.231.128 netmask 255.255.255.0 broadcast 192.168.110.255
Now edit the /etc/keepalived/keepalived.conf
mv /etc/keepalived/keepalived.conf /etc/keepalived/keepalived.conf.orig
vi /etc/keepalived/keepalived.confAdd following configuration:
vrrp_script check_haproxy { script "pkill -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state MASTER interface ens33 virtual_router_id 51 priority 101 advert_int 1 virtual_ipaddress { 192.168.231.140 } track_script { check_haproxy } }
Repeat the same in pghelp02
vi /etc/keepalived/keepalived.confAdd following configuration:
pghelp02 file should look like below
vrrp_script check_haproxy { script "pkill -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 100 advert_int 1 virtual_ipaddress { 192.168.231.140 } track_script { check_haproxy } }
Repeat the same in pghelp03
vi /etc/keepalived/keepalived.confAdd following configuration:
pghelp03 file should look like below
vrrp_script check_haproxy { script "pkill -0 haproxy" interval 2 weight 2 } vrrp_instance VI_1 { state BACKUP interface ens33 virtual_router_id 51 priority 100 advert_int 1 virtual_ipaddress { 192.168.231.140 } track_script { check_haproxy } }
Start the keepalived service on all the machines.
systemctl start keepalived
systemctl enable keepalived
systemctl status keepalivedCheck on your (pghelp01) node to see if your (ens33) network interface has config
ured with an additional shared IP (192.168.231.140) with the command below
ip addr show ens33the output should look like this
[root@pghelp01 ~]# ip addr show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:5c:75:6a brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.231.128/24 brd 192.168.110.255 scope global dynamic noprefixroute ens33
valid_lft 1107sec preferred_lft 1107sec
inet 192.168.231.140/32 scope global ens33
valid_lft forever preferred_lft forever
inet6 fe80::20c:29ff:fe5c:756a/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@pghelp01 ~]#
and you cannot see 192.168.231.140 in pghelp02 and pghelp03, because it’s a floating IP and will be moved to pghelp02 or pghelp03 when p1 is unavailable.
[root@pghelp02 ~]# ip addr show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:fc:55:9d brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.231.129/24 brd 192.168.110.255 scope global dynamic noprefixroute ens33
valid_lft 1110sec preferred_lft 1110sec
inet6 fe80::20c:29ff:fefc:559d/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@pghelp02 ~]#
[root@pghelp03 ~]# ip addr show ens33
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:7d:46:36 brd ff:ff:ff:ff:ff:ff
altname enp2s1
inet 192.168.231.130/24 brd 192.168.110.255 scope global dynamic noprefixroute ens33
valid_lft 1120sec preferred_lft 1120sec
inet6 fe80::20c:29ff:fe7d:4636/64 scope link noprefixroute
valid_lft forever preferred_lft forever
[root@pghelp03 ~]#Set up HAProxy for PostgreSQL 17 HA with Patroni
Install HAProxy [all machines]
dnf -y install haproxyConfigure HAProxy [all machines]
Edit haproxy.cfg file on your first node and repeat the same in pghelp02 and pghelp03 and make necessary changes in configuration files
mv /etc/haproxy/haproxy.cfg /etc/haproxy/haproxy.cfg.orig
vi /etc/haproxy/haproxy.cfgAdd following configuration:
global
maxconn 1000
defaults
mode tcp
log global
option tcplog
retries 3
timeout queue 1m
timeout connect 4s
timeout client 60m
timeout server 60m
timeout check 5s
maxconn 900
listen stats
mode http
bind *:7000
stats enable
stats uri /
listen primary
bind 192.168.231.140:5000
option httpchk OPTIONS /master
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server pghelp01 192.168.231.128:5432 maxconn 100 check port 8008
server pghelp02 192.168.231.129:5432 maxconn 100 check port 8008
server pghelp03 192.168.231.130:5432 maxconn 100 check port 8008
listen standby
bind 192.168.231.140:5001
balance roundrobin
option httpchk OPTIONS /replica
http-check expect status 200
default-server inter 3s fall 3 rise 2 on-marked-down shutdown-sessions
server pghelp01 192.168.231.128:5432 maxconn 100 check port 8008
server pghelp02 192.168.231.129:5432 maxconn 100 check port 8008
server pghelp03 192.168.231.130:5432 maxconn 100 check port 8008copy the file to pghelp02 and pghelp03
[root@pghelp01 ~]# scp /etc/haproxy/haproxy.cfg pghelp02:/etc/haproxy/haproxy.cfg
root@pghelp02's password:
haproxy.cfg 100% 1218 676.0KB/s 00:00
[root@pghelp01 ~]# scp /etc/haproxy/haproxy.cfg pghelp03:/etc/haproxy/haproxy.cfg
root@pghelp03's password:
haproxy.cfg 100% 1218 491.5KB/s 00:00
[root@pghelp01 ~]#
start haproxy service [all machines]
systemctl start haproxy
systemctl enable haproxy
systemctl status haproxy
Install PostgreSQL 17 with Patroni for PostgreSQL 17 HA with Patroni
Install Patroni [all machines]
dnf -y install patroni
dnf -y install patroni-etcd
dnf -y install watchdog
sudo ln -s /usr/local/bin/patronictl /bin/patronictl
patronictl –helpConfigure Patroni [all machines accordingly]
Create a configuration file for Patroni on your first node (pghelp01) in our case, like below:
mkdir -p /etc/patroni
vi /etc/patroni/patroni.ymlEdit the file with following content (pghelp01)
scope: postgres
namespace: /db/
name: pghelp01
restapi:
listen: 192.168.231.128:8008
connect_address: 192.168.231.128:8008
etcd3:
hosts: 192.168.231.128:2379,192.168.231.129:2379,192.168.231.130:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
pg_hba:
- host replication replicator 192.168.231.128/0 md5
- host replication replicator 192.168.231.129/0 md5
- host replication replicator 192.168.231.130/0 md5
- host replication all 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
postgresql:
listen: 192.168.231.128:5432
connect_address: 192.168.231.128:5432
data_dir: /u01/pgsql/17
bin_dir: /usr/pgsql-17/bin
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
parameters:
unix_socket_directories: '/run/postgresql/'
watchdog:
mode: required
device: /dev/watchdog
safety_margin: 5
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: falseIn pghelp02, edit the file with following content
scope: postgres
namespace: /db/
name: pghelp02
restapi:
listen: 192.168.231.129:8008
connect_address: 192.168.231.129:8008
etcd3:
hosts: 192.168.231.128:2379,192.168.231.129:2379,192.168.231.130:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
pg_hba:
- host replication replicator 192.168.231.128/0 md5
- host replication replicator 192.168.231.129/0 md5
- host replication replicator 192.168.231.130/0 md5
- host replication all 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
postgresql:
listen: 192.168.231.129:5432
connect_address: 192.168.231.129:5432
data_dir: /u01/pgsql/17
bin_dir: /usr/pgsql-17/bin
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
parameters:
unix_socket_directories: '/run/postgresql/'
watchdog:
mode: required
device: /dev/watchdog
safety_margin: 5
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: falseIn pghelp03, edit the file with the following content
scope: postgres
namespace: /db/
name: pghelp03
restapi:
listen: 192.168.231.130:8008
connect_address: 192.168.231.130:8008
etcd3:
hosts: 192.168.231.128:2379,192.168.231.129:2379,192.168.231.130:2379
bootstrap:
dcs:
ttl: 30
loop_wait: 10
retry_timeout: 10
maximum_lag_on_failover: 1048576
postgresql:
use_pg_rewind: true
pg_hba:
- host replication replicator 192.168.231.128/0 md5
- host replication replicator 192.168.231.129/0 md5
- host replication replicator 192.168.231.130/0 md5
- host replication all 0.0.0.0/0 md5
- host all all 0.0.0.0/0 md5
postgresql:
listen: 192.168.231.130:5432
connect_address: 192.168.231.130:5432
data_dir: /u01/pgsql/17
bin_dir: /usr/pgsql-17/bin
authentication:
replication:
username: replicator
password: replicator
superuser:
username: postgres
password: postgres
parameters:
unix_socket_directories: '/run/postgresql/'
watchdog:
mode: required
device: /dev/watchdog
safety_margin: 5
tags:
nofailover: false
noloadbalance: false
clonefrom: false
nosync: falseEnable Watchdog [all machines]
Edit /etc/watchdog.conf to enable software watchdog:
vi /etc/watchdog.confUncomment following line:
watchdog-device = /dev/watchdog
Execute following commands to activate watchdog:
mknod /dev/watchdog c 10 130
modprobe softdog
chown postgres /dev/watchdogFor example.,
[root@pghelp03 ~]# mknod /dev/watchdog c 10 130
[root@pghelp03 ~]# modprobe softdog
[root@pghelp03 ~]# chown postgres /dev/watchdog
[root@pghelp03 ~]#
Add the necessary permissions for postgres user to create data directory [all machines]
mkdir -p /u01
chown -R postgres:postgres /u01
start patroni on pghelp01
systemctl start patroniand the log should look like this
Mar 25 11:59:30 pghelp01 systemd[1]: Started Runners to orchestrate a high-availability PostgreSQL. Mar 25 11:59:30 pghelp01 patroni[39401]: 2024-03-25 11:59:30,810 INFO: Selected new etcd server http://192.168.231.130:2379 Mar 25 11:59:30 pghelp01 patroni[39401]: 2024-03-25 11:59:30,836 INFO: No PostgreSQL configuration items changed, nothing to reload. Mar 25 11:59:30 pghelp01 patroni[39401]: 2024-03-25 11:59:30,889 INFO: Lock owner: None; I am pghelp01 Mar 25 11:59:30 pghelp01 patroni[39401]: 2024-03-25 11:59:30,990 INFO: trying to bootstrap a new cluster Mar 25 11:59:31 pghelp01 patroni[39409]: The files belonging to this database system will be owned by user "postgres". Mar 25 11:59:31 pghelp01 patroni[39409]: This user must also own the server process. Mar 25 11:59:31 pghelp01 patroni[39409]: The database cluster will be initialized with locale "en_IN.UTF-8". Mar 25 11:59:31 pghelp01 patroni[39409]: The default database encoding has accordingly been set to "UTF8". Mar 25 11:59:31 pghelp01 patroni[39409]: The default text search configuration will be set to "english". Mar 25 11:59:31 pghelp01 patroni[39409]: Data page checksums are disabled. Mar 25 11:59:31 pghelp01 patroni[39409]: creating directory /u01/pgsql/17 ... ok Mar 25 11:59:31 pghelp01 patroni[39409]: creating subdirectories ... ok Mar 25 11:59:31 pghelp01 patroni[39409]: selecting dynamic shared memory implementation ... posix Mar 25 11:59:31 pghelp01 patroni[39409]: selecting default max_connections ... 100 Mar 25 11:59:31 pghelp01 patroni[39409]: selecting default shared_buffers ... 128MB Mar 25 11:59:31 pghelp01 patroni[39409]: selecting default time zone ... Asia/Kolkata Mar 25 11:59:31 pghelp01 patroni[39409]: creating configuration files ... ok Mar 25 11:59:31 pghelp01 patroni[39409]: running bootstrap script ... ok Mar 25 11:59:32 pghelp01 patroni[39409]: performing post-bootstrap initialization ... ok Mar 25 11:59:32 pghelp01 patroni[39409]: syncing data to disk ... ok Mar 25 11:59:32 pghelp01 patroni[39409]: initdb: warning: enabling "trust" authentication for local connections Mar 25 11:59:32 pghelp01 patroni[39409]: initdb: hint: You can change this by editing pg_hba.conf or using the option -A, or --auth-local and --auth-host, the next time you run initdb. Mar 25 11:59:32 pghelp01 patroni[39409]: Success. You can now start the database server using: Mar 25 11:59:32 pghelp01 patroni[39409]: /usr/pgsql-16/bin/pg_ctl -D /u01/pgsql/16 -l logfile start Mar 25 11:59:32 pghelp01 patroni[39401]: 2024-03-25 11:59:32,537 INFO: establishing a new patroni heartbeat connection to postgres Mar 25 11:59:32 pghelp01 patroni[39426]: 2024-03-25 11:59:32.646 IST [39426] LOG: redirecting log output to logging collector process Mar 25 11:59:32 pghelp01 patroni[39426]: 2024-03-25 11:59:32.646 IST [39426] HINT: Future log output will appear in directory "log". Mar 25 11:59:32 pghelp01 patroni[39401]: 2024-03-25 11:59:32,660 INFO: postmaster pid=39426 Mar 25 11:59:32 pghelp01 systemd[1]: Starting SSSD Kerberos Cache Manager... Mar 25 11:59:32 pghelp01 systemd[1]: Started SSSD Kerberos Cache Manager. Mar 25 11:59:32 pghelp01 sssd_kcm[39437]: Starting up Mar 25 11:59:32 pghelp01 patroni[39431]: 192.168.231.128:5432 - accepting connections Mar 25 11:59:32 pghelp01 patroni[39438]: 192.168.231.128:5432 - accepting connections Mar 25 11:59:32 pghelp01 patroni[39401]: 2024-03-25 11:59:32,759 INFO: establishing a new patroni heartbeat connection to postgres Mar 25 11:59:32 pghelp01 patroni[39401]: 2024-03-25 11:59:32,829 INFO: running post_bootstrap Mar 25 11:59:32 pghelp01 patroni[39401]: 2024-03-25 11:59:32,859 INFO: Software Watchdog activated with 25 second timeout, timing slack 15 seconds Mar 25 11:59:33 pghelp01 patroni[39401]: 2024-03-25 11:59:33,060 INFO: initialized a new cluster Mar 25 11:59:33 pghelp01 patroni[39401]: 2024-03-25 11:59:33,302 INFO: establishing a new patroni restapi connection to postgres Mar 25 11:59:38 pghelp01 haproxy[34627]: [WARNING] (34627) : Server primary/p4 is UP, reason: Layer7 check passed, code: 200, check duration: 8ms. 1 active and 0 backup servers online. 0 sessions requeued, 0 total in queue. Mar 25 11:59:43 pghelp01 patroni[39401]: 2024-03-25 11:59:43,013 INFO: no action. I am (pghelp01), the leader with the lock Mar 25 11:59:43 pghelp01 haproxy[34627]: [WARNING] (34627) : Server standby/p5 is UP, reason: Layer7 check passed, code: 200, check duration: 5ms. 1 active and 0 backup servers online. 0 sessions requeued, 0 total in queue. Mar 25 11:59:44 pghelp01 haproxy[34627]: [WARNING] (34627) : Server standby/p6 is UP, reason: Layer7 check passed, code: 200, check duration: 3ms. 2 active and 0 backup servers online. 0 sessions requeued, 0 total in queue. Mar 25 11:59:53 pghelp01 patroni[39401]: 2024-03-25 11:59:53,005 INFO: no action. I am (pghelp01), the leader with the lock
on pghelp02, start the patroni
systemctl start patroniyou should see log like this
Mar 25 11:59:37 pghelp02 systemd[1]: Started Runners to orchestrate a high-availability PostgreSQL.
Mar 25 11:59:38 pghelp02 patroni[37998]: 2024-03-25 11:59:38,176 INFO: Selected new etcd server http://192.168.231.129:2379
Mar 25 11:59:38 pghelp02 patroni[37998]: 2024-03-25 11:59:38,231 INFO: No PostgreSQL configuration items changed, nothing to reload.
Mar 25 11:59:38 pghelp02 patroni[37998]: 2024-03-25 11:59:38,283 INFO: Lock owner: pghelp01; I am pghelp02
Mar 25 11:59:38 pghelp02 patroni[37998]: 2024-03-25 11:59:38,328 INFO: trying to bootstrap from leader 'pghelp01'
Mar 25 11:59:38 pghelp02 systemd[1]: Starting SSSD Kerberos Cache Manager...
Mar 25 11:59:38 pghelp02 systemd[1]: Started SSSD Kerberos Cache Manager.
Mar 25 11:59:38 pghelp02 sssd_kcm[38007]: Starting up
Mar 25 11:59:38 pghelp02 patroni[38005]: WARNING: skipping special file "./.s.PGSQL.5432"
Mar 25 11:59:39 pghelp02 patroni[38005]: WARNING: skipping special file "./.s.PGSQL.5432"
Mar 25 11:59:39 pghelp02 patroni[37998]: 2024-03-25 11:59:39,449 INFO: replica has been created using basebackup
Mar 25 11:59:39 pghelp02 patroni[37998]: 2024-03-25 11:59:39,451 INFO: bootstrapped from leader 'pghelp01'
Mar 25 11:59:39 pghelp02 patroni[37998]: 2024-03-25 11:59:39,927 INFO: establishing a new patroni heartbeat connection to postgres
Mar 25 11:59:40 pghelp02 patroni[37998]: 2024-03-25 11:59:40,120 INFO: establishing a new patroni heartbeat connection to postgres
Mar 25 11:59:40 pghelp02 patroni[38017]: 2024-03-25 11:59:40.333 IST [38017] LOG: redirecting log output to logging collector process
Mar 25 11:59:40 pghelp02 patroni[38017]: 2024-03-25 11:59:40.333 IST [38017] HINT: Future log output will appear in directory "log".
Mar 25 11:59:40 pghelp02 patroni[37998]: 2024-03-25 11:59:40,359 INFO: postmaster pid=38017
Mar 25 11:59:40 pghelp02 patroni[38022]: 192.168.231.129:5432 - rejecting connections
Mar 25 11:59:40 pghelp02 patroni[38024]: 192.168.231.129:5432 - accepting connections
Mar 25 11:59:40 pghelp02 patroni[37998]: 2024-03-25 11:59:40,427 INFO: Lock owner: pghelp01; I am pghelp02
Repeat the same in pghelp03
Check patroni member nodes:
patronictl -c /etc/patroni/patroni.yml list
The output should look like this
[root@pghelp01 ~]# patronictl -c /etc/patroni/patroni.yml list + Cluster: postgres (7350184426948975095) ---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------+-----------------+---------+-----------+----+-----------+ | pghelp01 | 192.168.231.128 | Leader | running | 1 | | | pghelp02 | 192.168.231.129 | Replica | streaming | 1 | 0 | | pghelp03 | 192.168.231.130 | Replica | streaming | 1 | 0 | +----------+-----------------+---------+-----------+----+-----------+ [root@pghelp01 ~]#
Check if you can connect from psql client (as postgres user)
psql -h 192.168.231.140 -p 5000
and you should get something like this
[root@pghelp01 ~]# su - postgres [postgres@pghelp01 ~]$ psql -h 192.168.231.140 -p 5000 Password for user postgres: psql (17.1) Type "help" for help.
Create a sample table and we will use this table for failure scenarios
create table emp(id int, sal int);
Test switchover
[postgres@pghelp01 ~]$ patronictl -c /etc/patroni/patroni.yml switchover Current cluster topology + Cluster: postgres (7350184426948975095) ---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------+-----------------+---------+-----------+----+-----------+ | pghelp01 | 192.168.231.128 | Leader | running | 1 | | | pghelp02 | 192.168.231.129 | Replica | streaming | 1 | 0 | | pghelp03 | 192.168.231.130 | Replica | streaming | 1 | 0 | +----------+-----------------+---------+-----------+----+-----------+ Primary [pghelp01]: Candidate ['pghelp02', 'pghelp03'] []: pghelp02 When should the switchover take place (e.g. 2024-03-25T13:15 ) [now]: Are you sure you want to switchover cluster postgres, demoting current leader pghelp01? [y/N]: y 2024-03-25 12:16:02.99139 Successfully switched over to "pghelp02" + Cluster: postgres (7350184426948975095) -------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------+-----------------+---------+---------+----+-----------+ | pghelp01 | 192.168.231.128 | Replica | stopped | | unknown | | pghelp02 | 192.168.231.129 | Leader | running | 2 | | | pghelp03 | 192.168.231.130 | Replica | running | 1 | 0 | +----------+-----------------+---------+---------+----+-----------+ [postgres@pghelp01 ~]$ .. (after few seconds) .. [postgres@pghelp01 ~]$ patronictl -c /etc/patroni/patroni.yml list + Cluster: postgres (7350184426948975095) ---------+----+-----------+ | Member | Host | Role | State | TL | Lag in MB | +----------+-----------------+---------+-----------+----+-----------+ | pghelp01 | 192.168.231.128 | Replica | streaming | 2 | 0 | | pghelp02 | 192.168.231.129 | Leader | running | 2 | | | pghelp03 | 192.168.231.130 | Replica | streaming | 2 | 0 | +----------+-----------------+---------+-----------+----+-----------+ [postgres@pghelp01 ~]$
A simple ping test can also serve the purpose
Write test
while true; do psql -Upostgres -h192.168.231.140 -p5000 -c "select inet_server_addr(),now()::timestamp;" -c "insert into emp values(1,1)" -t; sleep 1; done
The write test result should look like this
[postgres@pghelp01 ~]$ while true; do psql -Upostgres -h192.168.231.140 -p5000 -c "select inet_server_addr(),now()::timestamp;" -c "insert into emp values(1,1)" -t; sleep 1; done
Output snippet
192.168.231.129 | 2024-03-25 12:21:59.547371
INSERT 0 1
192.168.231.129 | 2024-03-25 12:22:00.592847
..
INSERT 0 1
192.168.231.129 | 2024-03-25 12:22:10.920696
INSERT 0 1
192.168.231.129 | 2024-03-25 12:22:11.950185
INSERT 0 1
<- autofailover in progress ->
psql: error: connection to server at “192.168.231.140”, port 5000 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
psql: error: connection to server at “192.168.231.140”, port 5000 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
psql: error: connection to server at “192.168.231.140”, port 5000 failed: server closed the connection unexpectedly
This probably means the server terminated abnormally
before or while processing the request.
192.168.231.128 | 2024-03-25 12:22:25.074037
INSERT 0 1
192.168.231.128 | 2024-03-25 12:22:26.099442
Read test
while true; do psql -Upostgres -h192.168.231.140 -p5001 -c "select inet_server_addr(),now()::timestamp;" -c " select * from emp" -t; sleep 1; done
Words from postgreshelp
End-to-End PostgreSQL Administration Training: Click here


