This post answers the following question with comprehensive details.
How much memory you need to give to your shared buffers in PostgreSQL and why?
Bonus!! Why my RDS postgreSQL shared buffers uses 25% of system RAM where as Aurora’s shared buffers is 75%?
The answer is here.
Table of Contents
Understanding OS Cache vs Shared Buffers in PostgreSQL
Before we begin, I have a question for you.
what is the role of BGWriter in PostgreSQL?
And if your answer is “it writes the dirty buffers to disk”, that’s wrong.
It actually writes the dirty buffers to OS cache and then a separate system call is made to flush the pages to disk from OS cache.
Confused?
Let’s understand it.
Because of its light weight nature, PostgreSQL has to highly depend on the operating system cache.It depends on Operating system to know about the file system, disk layout and how to read and write the data files.
The following picture gives you a glimpse of how the data flows between the disk and shared buffers.
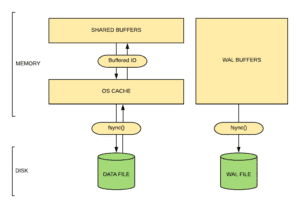
here, whenever you issue a “select * from emp”, your data is actually loaded into OS cache and then to shared buffers. In the same way, when you try to flush the dirty buffers to disk, the pages are actually flushed to OS cache and then to disk through a separate system call called fsync().
Here, The PostgreSQL is actually duplicating what OS does which means OS cache and shared_buffers can hold the same pages.
This may lead for space wastage, but remember the OS cache is using a simple LRU and not a database optimized clock sweep algorithm. Once the pages take a hit on shared_buffers, the reads never reach the OS cache, and if there are any duplicates, they get removed easily.
Can I influence the Operating system’s fsync() to flush dirty buffers to disk?
Yes, with the parameter in postgresql.conf file
bgwriter_flush_after (integer) – default 512 kB
Whenever more than this amount of data has been written by the background writer, attempt to force the OS to issue these writes to the underlying storage. Doing so will limit the amount of dirty data in the kernel’s page cache, reducing the likelihood of stalls when an fsync is issued at the end of a checkpoint, or when the OS writes data back in larger batches in the background. It is taken as blocks, that is BLCKSZ bytes, typically 8kB.
Not only bgwriter, in PostgreSQL even checkpointer process and user backend process can also writer dirty buffers from shared buffers to OS cache. Even there we can influence Operating system’s fsync() with checkpoint_flush_after and backend_flush_after commands respectively(though discussion about checkpointer and backend process is beyond the scope of this post).
Also read: comprehensive guide on checkpointer process
What if I give too little value to OS Cache ?
As discussed above, Once a page is marked dirty, it gets flushed to the OS cache which then writes to disk. This is where the OS has more freedom to schedule I/O based on the incoming traffic. If the OS cache size is less, then it cannot re-order the writes and optimize I/O. This is particularly important for a write heavy workload. So the OS cache size is important as well.
What if I give too little value to Shared Buffers Cache ?
Simple, though OS cache is used for caching, your actual database operations are performed in Shared buffers. so it is good idea to give enough space in shared buffers.
What is optimal value then?
PostgreSQL recommends you to give 25% of your system memory to shared buffers and you can always try changing the values as per your environment.
How to view the contents of shared buffers?
PG buffer cache extension helps us see the data in shared buffers in real time. Collects information from shared_buffers and puts it inside of pg_buffercache for viewing.
create extension pg_buffercache;
After installing the extension, execute the below query to check the contents of shared buffers.
SELECT c.relname , pg_size_pretty(count(*) * 8192) as buffered , round(100.0 * count(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent , round(100.0 * count(*) * 8192 / pg_relation_size(c.oid),1) AS percent_of_relation FROM pg_class c INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database()) WHERE pg_relation_size(c.oid) > 0 GROUP BY c.oid, c.relname ORDER BY 3 DESC LIMIT 10;
The sample output would be
postgres=# SELECT c.relname
postgres-# , pg_size_pretty(count(*) * 8192) as buffered
postgres-# , round(100.0 * count(*) / ( SELECT setting FROM pg_settings WHERE name='shared_buffers')::integer,1) AS buffers_percent
postgres-# , round(100.0 * count(*) * 8192 / pg_relation_size(c.oid),1) AS percent_of_relation
postgres-# FROM pg_class c
postgres-# INNER JOIN pg_buffercache b ON b.relfilenode = c.relfilenode
postgres-# INNER JOIN pg_database d ON (b.reldatabase = d.oid AND d.datname = current_database())
postgres-# WHERE pg_relation_size(c.oid) > 0
postgres-# GROUP BY c.oid, c.relname
postgres-# ORDER BY 3 DESC
postgres-# LIMIT 10;
relname | buffered | buffers_percent | percent_of_relation
---------------------------+------------+-----------------+---------------------
pg_operator | 80 kB | 0.1 | 71.4
pg_depend_reference_index | 96 kB | 0.1 | 27.9
pg_am | 8192 bytes | 0.0 | 100.0
pg_amproc | 24 kB | 0.0 | 100.0
pg_cast | 8192 bytes | 0.0 | 50.0
pg_depend | 64 kB | 0.0 | 14.0
pg_index | 32 kB | 0.0 | 100.0
pg_description | 40 kB | 0.0 | 14.3
pg_language | 8192 bytes | 0.0 | 100.0
pg_amop | 40 kB | 0.0 | 83.3
(10 rows)
How can I see if my data is actually cached at OS level?
To check the data cached at OS level, we need to install the package pgfincore.
This an external module, that gives information on how the OS caches the pages. It is pretty low level and also very powerful.
Download the pgfincore and follow the below steps.
As root user: export PATH=/usr/local/pgsql/bin:$PATH //Set the path to point pg_config. tar -xvf pgfincore-v1.1.1.tar.gz cd pgfincore-1.1.1 make clean make make install Now connect to PG and run below command postgres=# CREATE EXTENSION pgfincore;
Now execute the below command to check the buffers at OS Level.
select c.relname,pg_size_pretty(count(*) * 8192) as pg_buffered,
round(100.0 * count(*) /
(select setting
from pg_settings
where name='shared_buffers')::integer,1)
as pgbuffer_percent,
round(100.0*count(*)*8192 / pg_table_size(c.oid),1) as percent_of_relation,
( select round( sum(pages_mem) * 4 /1024,0 )
from pgfincore(c.relname::text) )
as os_cache_MB ,
round(100 * (
select sum(pages_mem)*4096
from pgfincore(c.relname::text) )/ pg_table_size(c.oid),1)
as os_cache_percent_of_relation,
pg_size_pretty(pg_table_size(c.oid)) as rel_size
from pg_class c
inner join pg_buffercache b on b.relfilenode=c.relfilenode
inner join pg_database d on (b.reldatabase=d.oid and d.datname=current_database()
and c.relnamespace=(select oid from pg_namespace where nspname='public'))
group by c.oid,c.relname
order by 3 desc limit 30;
The sample output of the above command is
relname |pg_buffered|pgbuffer_per|per_of_relation|os_cache_mb|os_cache_per_of_relation|rel_size ---------+-----------+------------+---------------+-----------+------------------------+-------- emp | 4091 MB | 99.9 | 49.3 | 7643 | 92.1 | 8301 MB
pg_buffered stands for how much data buffered in PostgreSQL buffer cache
pgbuffer_percent stands for pg_buffered/total_buffer_size *100
percent_of_relation stands for pg_buffered/total_relation_size * 100
os_cache_mb stands for how much a relation cached in OS
Here, our table emp has a size of 8301 MB and and 92% of its data is there in OS cache, at the same time 49.3% data is there in shared buffers, that is approximately 50% data is redundant.
Bonus!!
Why Aurora’s PostgreSQL dedicate 75% of its RAM to shared buffers?
For RDS DB instances, the default value of the DB parameter group is set to 25% of total memory. But for Aurora DB instances, the default value of the DB parameter group is set to 75% of total memory. This is because Aurora PostgreSQL eliminates double buffering and doesn’t utilize file system cache. As a result, Aurora PostgreSQL can increase shared_buffers to improve performance. It’s a best practice to use the default value of 75% for the shared_buffers DB parameter when using Aurora PostgreSQL
As we all know work_mem, maintenance_work_mem and other local memory components are not part of shared buffers, in aurora if your application need a lot of work_mem or your application require more client connections, you met set shared_buffers value lesser than 75%.
Thank you for giving your valuable time to read the above information. I hope the content served your purpose in reaching out to the blog.
Suggestions for improvement of the blog are highly appreciable. Please contact us for any information/suggestions/feedback.
If you want to be updated with all our articles
please follow us on Facebook | Twitter
Please subscribe to our newsletter.
Very informative. Good blog
Thank you!! Share with your friends.
#LearningIsFun